
Po wielu latach poddałem się i zaszlachtowałem swój robiony chałupniczo CMS na korzyść wordpressa. Mam nadzieję że sprawi to że będę częściej publikował.
Spotkanie z TaskCompletionSource – Cz. 3 Niespełnione obietnice
Trzecią i ostatnią część artykułu poświęcam rzadkiemu ale bardzo trudnemu w analizie problemowi, który może pojawić się w czasie adaptacji API w wykorzystaniem TaskCompletionSource.
Czytaj dalej „Spotkanie z TaskCompletionSource – Cz. 3 Niespełnione obietnice”
Spotkanie z TaskCompletionSource – Cz. 2 Zdarzenia a zadania
Jedną z prób ogarnięcia asynchroniczności było wykorzystanie mechanizmu zdarzeń (event). Onegdaj istniały takie technologie jak WCF – służący do wystawiania na świat API po http oraz Silverlight, który miał robić to co dzisiaj Flash javascript. I jak się generowało klasy pozwalające korzystać z API WCF w SL to wynikowe klasy przypominały taki kod:
public class Proxy
{
void Method1(int argument);
event EventHandler<EventArgs<Result1>> Method1Completed;
event EventHandler<FailureEventArgs> Method1Failed;
void Method2();
event EventHandler<EventArgs<Result2>> Method1Completed;
event EventHandler<FailureEventArgs> Method1Failed;
}
Czytaj dalej „Spotkanie z TaskCompletionSource – Cz. 2 Zdarzenia a zadania”
Spotkanie z TaskCompletionSource – Cz. 1 I promise I will call back
Programowanie asynchroniczne w C# stało całkiem znośne od kiedy język ten posiada słowa kluczowe async i await. Rozwiązanie to tak udało się tak dobrze, że zaczyna pojawiać się w innych językach. VB.Net podobno już je ma (może któryś z czytelników już go używał i mógłby podzielić się swoimi doświadczeniami?), architekci projektujący C++ i Javascript także nad usilnie pracują na wdrożeniem podobnych mechanizmów.
Czytaj dalej „Spotkanie z TaskCompletionSource – Cz. 1 I promise I will call back”
Uruchamianie asynchronicznych metod bez await – ogólnie nie polecam
Podczas implementowania jednego z ficzerów aplikacji w pracy popełniłem metodę, w której uruchomiłem asynchroniczną metodę bez awaita.
Metoda miała i tak być odpalona w trybie „Fire and forget” więc uznałem wpisywanie tych kilkunastu znaków za stratę czasu i puściłem moduł na testy, które to testy moduł przeszedł. Jednak w przeciągu tygodnia użytkownicy zaczęli się skarżyć że aplikacja się przewraca w losowych momentach. Logi wskazywały, że mechanizm globalnej obsługi wyjątków loguje błąd o szczegółach podobnych do następujących:
Message:Wyjątków zadania nie zaobserwowano ani przez oczekiwanie na zadanie, ani przez uzyskanie dostępu do jego właściwości Exception. W wyniku tego niezaobserwowany wyjątek został wywołany ponownie przez wątek finalizatora.
Stack trace:
Stack trace:
Caused by:
Message:Zgłoszono wyjątek typu 'System.Exception’.
Stack trace:
Czytaj dalej „Uruchamianie asynchronicznych metod bez await – ogólnie nie polecam”
Nadmiarowo blokujące się przyciski z MVVM Light
MVVM Light jest bilioteką ułatwiającą tworzenie aplikacji wykorzystujących wzorzec MVVM. Jak do tej pory cieszy się moją sympatią w stopniu znacznie wyższym niż inne frameworki. Głownie dlatego, że nie robi rzeczy o które go nie proszę. Ostatnio jednak znalazłem ciekawe zachowanie tej biblioteki, które może powodować pojawianie się niedeterministycznych bugów.
MVMM Light posiada klasę RelayCommand pozwalającą szybko stworzyć pole typu ICommand (opis mechanizmu można znaleźć w wielu miejscach w internetach). Klasa ta posiada 2 parametry konstruktora: Execute typu Action – referencja do metody/lambdy wywoływanej po kliknięciu w przycisk, canExecute typu Func<bool> odwołanie do metody/lambdy wywoływane w celu określenia czy przycisk ma być włączony. Dodatkowo klasa posiada metodę RaiseCanExecuteChanged służącą do informowania przycisku o konieczności ponownego wywołania metody CanExecute.
Czytaj dalej „Nadmiarowo blokujące się przyciski z MVVM Light”
NCrunch – Jakie to, kurwa, dobre
Cytatem Youtubowego kucharza (Food Emperor) polecam wszystkim narzędzie wniesione do zespołu, w którym pracuję, przez nowego kolegę Sebastiana.
Wiem że o NCrunchu pisało już wielu. Jednak nikomu nie udało się mnie do niego przekonać, więc jest pewnie wielu innych sceptyków tego narzędzia i do nich właśnie jest ten artykuł.
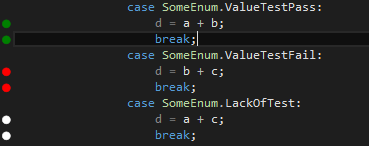
Jest to narzędzie pełniące rolę sumienia dla osób stosujących TDD. Każda linijka kodu C#-owego jest oznaczona kropą: białą gdy brakuje testów ją pokrywajacych, czerwoną gdy jakiś test nie przechodzi i zieloną gdy wszystko jest OK.
4Developers 2015 okiem Szoguna
Od kilku lat fundacja Proidea organizuje konferencję 4Developers. Uczestniczyłem w niej już kilkukrotnie i postanowiłem wybrać się także w tym roku.
W poprzednich latach konferencja odbywała się w różnych miastach, jednak w tym roku organizatorzy postanowili nie zmieniać dobrej miejscówki i podobnie jak rok temu jako lokalizację wybrali Hotelu Gromada w Warszawie.
Aktualizacja ASP.Net Identity do wesji 2
Ostatnimi czasy w jednym z projektów pociągnąłem sobie aktualizacje bibliotek przez Nuget’a. A że byłem leniwy to pociągnąłem je jak leci, nie patrząc co aktualizuje o change logu poszczególnych bibliotek nie mówiąc.
Nie róbcie tego w domu!
Jedną z aktualizacji była nowa wersja mechanizmu ASP.Net Identity. Aktualizacja zmieniła encje wykorzystywane przez mechanizm, nie zmieniła jednak bazy danych (być może ze względu na fakt iż nie korzystam z mechanizmu migracji).
Fakt ten można dość łatwo przeoczyć, wystarczy, że podczas testowania ręcznego nie wykona się żadnej operacji związanej z autoryzacją. Ponieważ miałem aktywną sesję sprzed aktualizacji nie musiałem się ani logować, ani rejestrować, wyjątek został więc zgłoszony tuż po wylogowaniu.
Gdy HtmlHelper to za mało
Czytając ostatnio o rozszerzeniach do klasy HtmlHelper, stwierdziłem że w wraz z rozwojem projektu ich różnorodność może stać się trudna do ogarnięcia i przydałoby się je pogrupować, zorganizować.
Zacząłem się więc zastanawiać jak takie rozwiązanie mogłoby wyglądać. Zaznaczam przy tym że sam tego jeszcze nie doświadczyłem, a koncepcje dalej przedstawione są raczej propozycjami niż wskazówkami.